
Throw Away The Vibes: Context Engineering Is All You Need - DDD Melbourne 2026
I had the opportunity to speak at DDD Melbourne 2026 about something that has consumed a lot of my thinking over the past year: how we actually get reliable results out of AI coding agents on real, messy codebases. The talk was titled “Throw Away The Vibes: Context Engineering Is All You Need,” and it distilled the practical lessons I have gathered while working on hypervelocity engineering workflows.
Many of us experience an intoxicating high the first time we use an AI coding agent. The “Hello World” example works flawlessly, and it feels like the future has arrived. Then we point the same agent at a large brownfield business repository and the magic evaporates. The frustration that follows is not a sign the tools are useless. It is a sign that we are feeding them the wrong context.
This talk was my attempt to explain why that happens, and what to do about it.
I presented earlier variations of this talk at the Melbourne .NET Meetup in September 2025 and at Apidays Australia 2025 in October 2025. Those slides are available here on Speaker Deck.
The video of the session is available on YouTube, and the slides are on Speaker Deck:
- Video of the talk: Throw Away The Vibes: Context Engineering Is All You Need - DDD Melbourne 2026
- Slides: Throw Away The Vibes: Context Engineering Is All You Need on Speaker Deck
- Interactive slides: Throw Away The Vibes — an interactive walkthrough of this talk
- Session details: Sessionize abstract
The talk premise, in short:
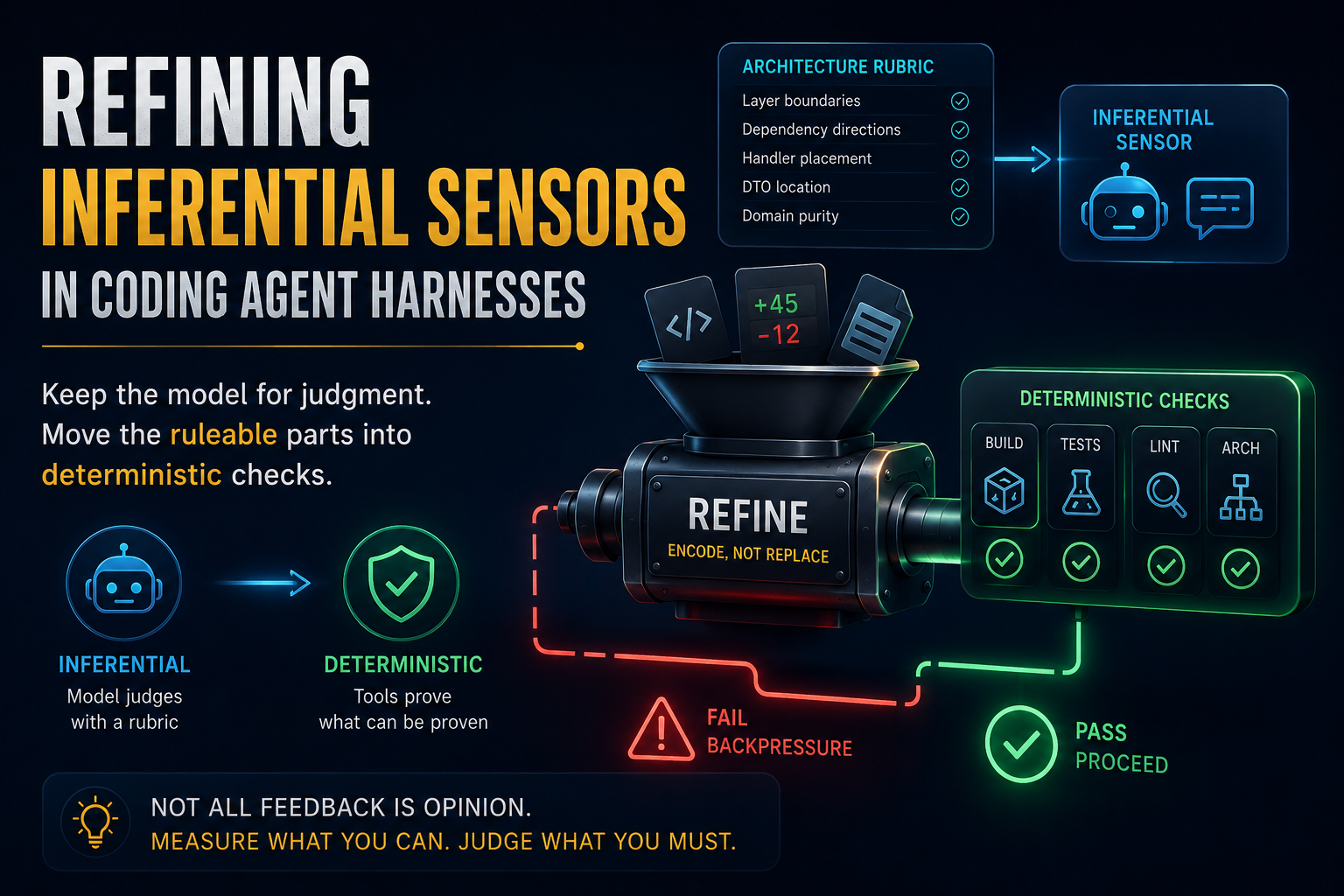
Coding agents are exceptional at generating text and code, but they have poor architectural and contextual judgement. The instinct when an agent produces bad code is to keep prompting it across many turns until it eventually gets things right. The better goal is to fix the context we feed the model so it produces an aligned, correct answer on the first attempt. That discipline is context engineering, and it matters far more than the “vibes.”
Beyond “Vibe Coding”
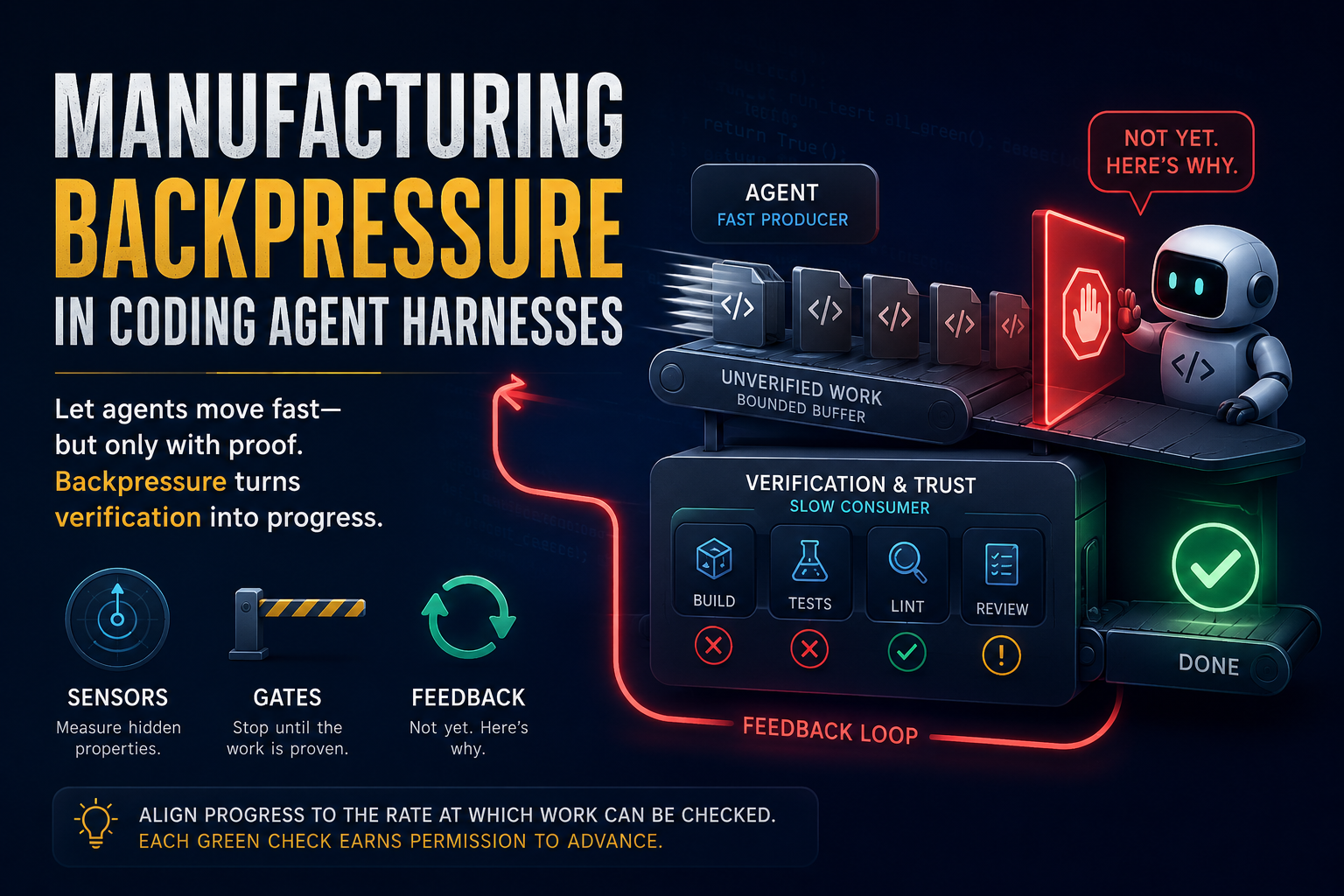
The core shift I wanted the audience to take away is a change in where we spend our effort. Vibe coding leans on a hopeful loop: let the agent generate something, notice it is wrong, and nudge it repeatedly until it converges. That loop is slow, it pollutes the conversation, and it rarely produces the quality we would accept from ourselves.
Agents are brilliant generators and weak judges. Once you internalize that asymmetry, the job changes. Instead of correcting bad output after the fact, you invest in the input. You curate exactly what the model sees before it writes a single line, so the very first answer lands close to correct.
Why a Long Context Window Is Not Enough
A common reaction is to assume the fix is simply more context. Just throw thousands of files into a million-token window and let the model sort it out. In practice, that approach makes things worse, and I walked through four failure modes of long context to explain why:
- Poisoning: If an agent hallucinates an error early in a thread and you keep using that thread, the bad information lingers in context and keeps corrupting everything generated afterwards.
- Distraction: Models apply different attention weights across a long prompt, so they routinely miss crucial details buried inside large blocks of text. This is the familiar “needle in a haystack” problem.
- Confusion: Superfluous or redundant information dilutes the signal and pulls the model toward irrelevant details.
- Clash: When contradictory pieces of code or information coexist in the same window, the model cannot reliably tell which one to trust.
The takeaway is not “less context” as a blanket rule. It is just enough context, delivered at the exact moment it is needed.
The Architecture of Context Engineering
I framed context engineering as a distinct layer that sits on top of traditional prompt engineering and directly beneath autonomous agents and opinionated engineering workflows. Prompt engineering shapes the instruction. Context engineering shapes the surrounding information environment that the instruction operates within.
Within that layer, I covered four architectural tactics for keeping context lean and relevant:
- Externalizing context: Move context out of volatile chat history and into a dedicated, shared space where the human and the agent can collaborate on the same source of truth.
- Tool loadout selection: Restrict the agent’s active tools, Model Context Protocol (MCP) servers, and skills to only what the immediate problem requires, so the model is not overwhelmed by options it does not need.
- Context compression: Use summarization to condense text while accepting some information loss, or compaction to swap full text for references and pointers the agent can retrieve later if it needs them.
- Isolation: Quarantine work into separate threads or sub-agent scopes so an individual agent is never drowned by the broader orchestration around it.
Practical Workflows
Theory is only useful if it changes how you work on Monday morning. I shared two workflows that turn these ideas into repeatable practice.
The Breadcrumb Protocol
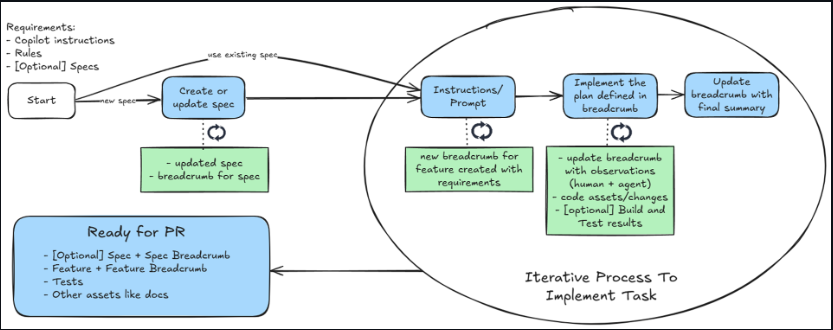
The first is a lightweight human-and-agent collaboration pattern built around a single markdown scratchpad file. I have written about this in detail in a previous post on the Breadcrumb Protocol, and it works like this:
- Plan and break down: Before any code is generated, the human and the agent co-author a task breakdown inside a markdown file.
- Iterate and log: As the agent executes, the file is continuously updated with state, decisions, and discoveries.
- Quarantine failures: When a chat session becomes polluted or goes off the rails, abandon the thread entirely. Keep the markdown scratchpad, document why the session failed, and feed that clean file into a brand-new session.
The scratchpad is the externalized context from the architecture section made concrete. The conversation is disposable. The file is durable.
The RPI (Research, Plan, Implement, Review) Flow
The second workflow scales the same principles across a team. Microsoft’s Industry Solutions Engineering team open-sourced the hve-core repository, which structures development into a constrained, multi-step pipeline:
- Research: A highly capable model, such as Claude Opus, analyses all the resource materials and produces a comprehensive baseline.
- Plan: A specialized planner decomposes that research into decoupled, granular steps.
- Implement: Independent sub-agents implement each sub-task in isolation, and in parallel where the work allows.
- Review: The resulting code is reviewed meticulously against the original research boundaries and the plan.
Each stage hands a clean, scoped context to the next, which is exactly the isolation tactic applied at the level of a whole development process.
Takeaways for 2026 and Beyond
I closed with a handful of practices I think are worth adopting:
- Watch your context threshold. Once an agent’s context window reaches roughly 60% capacity, compact it or start a fresh thread rather than pushing on.
- Treat sub-agents as functions. Resist anthropomorphizing them. Think of each one as a discrete, tightly scoped step with clear inputs and outputs.
- Shift the review left. AI-assisted tools produce large, rapid changes, so waiting until the pull request to review a giant wall of green text does not work. Review incrementally as the work happens.
- Master one harness. Stop chasing every new tool that launches. Pick a core stack, learn its specific context limitations, and get genuinely good at “harness engineering.”
The thread running through all of it is that human engineering expertise has not become less valuable. The role has shifted from typing code by hand toward high-level scaffolding, steering, and the systematic curation of context. The vibes can go. The engineering stays.
Recording
Slide Deck
A big thanks to everyone who helped organize DDD Melbourne and to everyone who came along to listen. If you have any thoughts or comments please leave them here. Thanks for taking the time to read this post.

Leave a comment