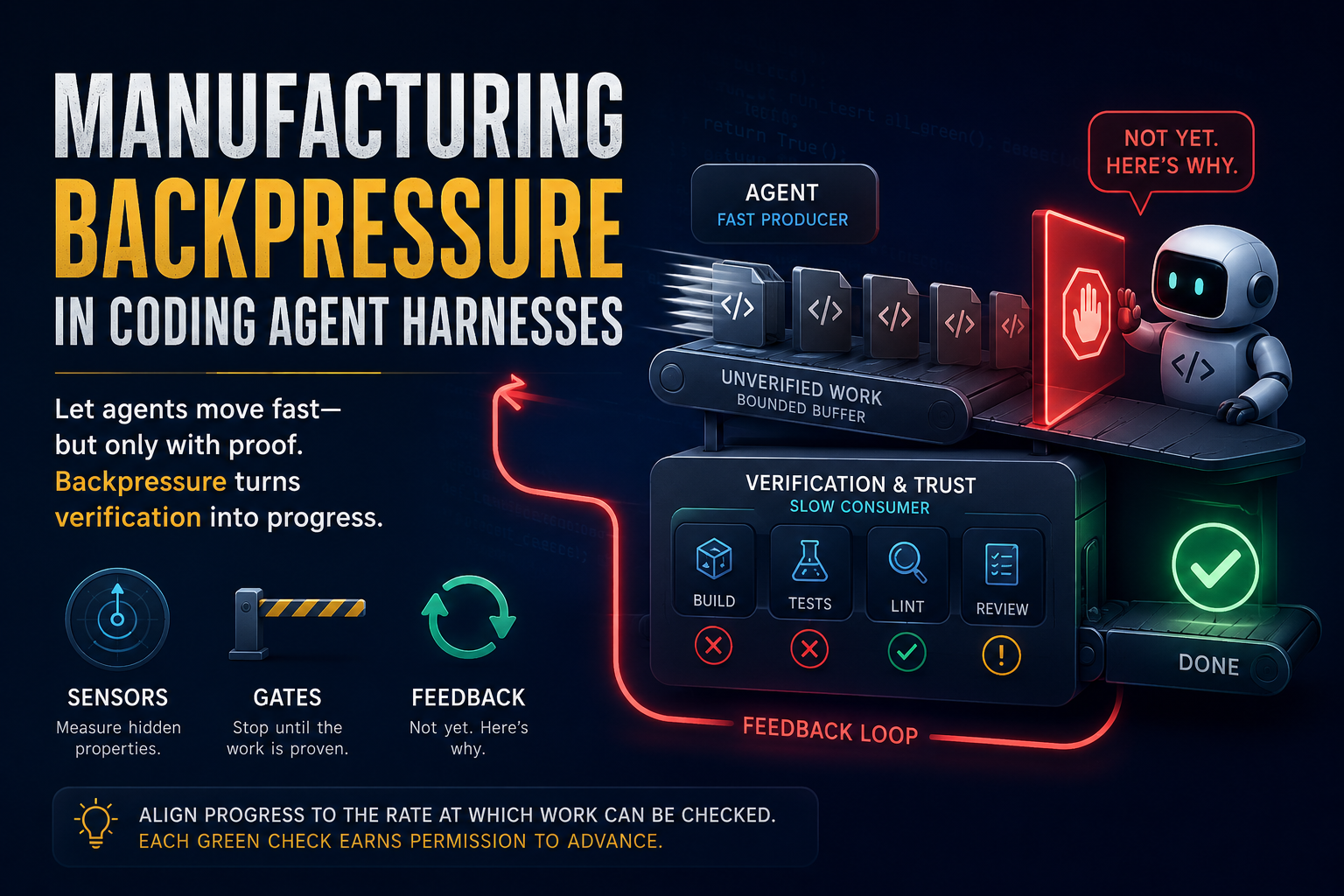
Harness Engineering
Building the tools, checks, and feedback loops around a coding agent: backpressure, sensors, and gates.

Agentic IAM
Identity, authorization, and delegation for AI agents, explored from first principles through real-world scenarios.
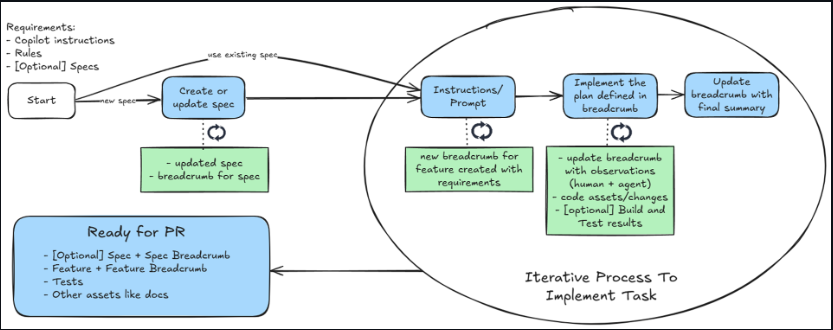
AI-Assisted Engineering
Practical patterns for reliable results from AI coding agents: breadcrumbs and context engineering.

DDD Melbourne 2026
Throw away the vibes. Why context engineering, not prompting, is what makes AI coding agents reliable on real codebases.
AAuth .NET SDK
The .NET SDK for AAuth — a four-party authorization protocol for AI agents where every HTTP request is cryptographically signed (RFC 9421) instead of using bearer tokens.
PromptyDumpty
A lightweight, universal package manager (on PyPI) for AI coding-assistant artifacts — prompts, instructions, rules and workflows — across Copilot, Claude, Cursor, Gemini and more.
AI-Powered VEX Generation
A GitHub Copilot–driven security workflow that scans for CVEs, analyses real exploitability, and generates OpenVEX-compliant documents using MCP tools.

Macro Data Refinement
A browser-based puzzle game inspired by the “mysterious and important” refinement work from the TV show Severance.

LLM Planning & Knowledge Providers
Four approaches to agentic planning workflows — LangChain Plan-and-Execute, AutoGen group chat, and Dapr virtual actors/workflows — connecting LLMs to external “knowledge providers” via APIs and MCP.

MCP Server as an OAuth Resource Server
An influential proposal — adopted into the 2025-06-18 MCP spec — to treat MCP servers as OAuth resource servers so they plug into existing identity providers instead of rolling their own.

API Days Australia 2024
An engineer’s perspective on the hard-earned lessons, risks, and realities of building with LLMs.

PromptFlow Serve Benchmarking
A Microsoft ISE engineering blog comparing WSGI/sync vs ASGI/async PromptFlow Serve runners — backpressure, throughput, and practical recommendations.
NEasyAuthMiddleware
ASP.NET Core middleware (on NuGet) for Azure App Service Authentication (EasyAuth) — hydrates HttpContext.User from EasyAuth headers, with customizable claim mapping and local-debug mocking.
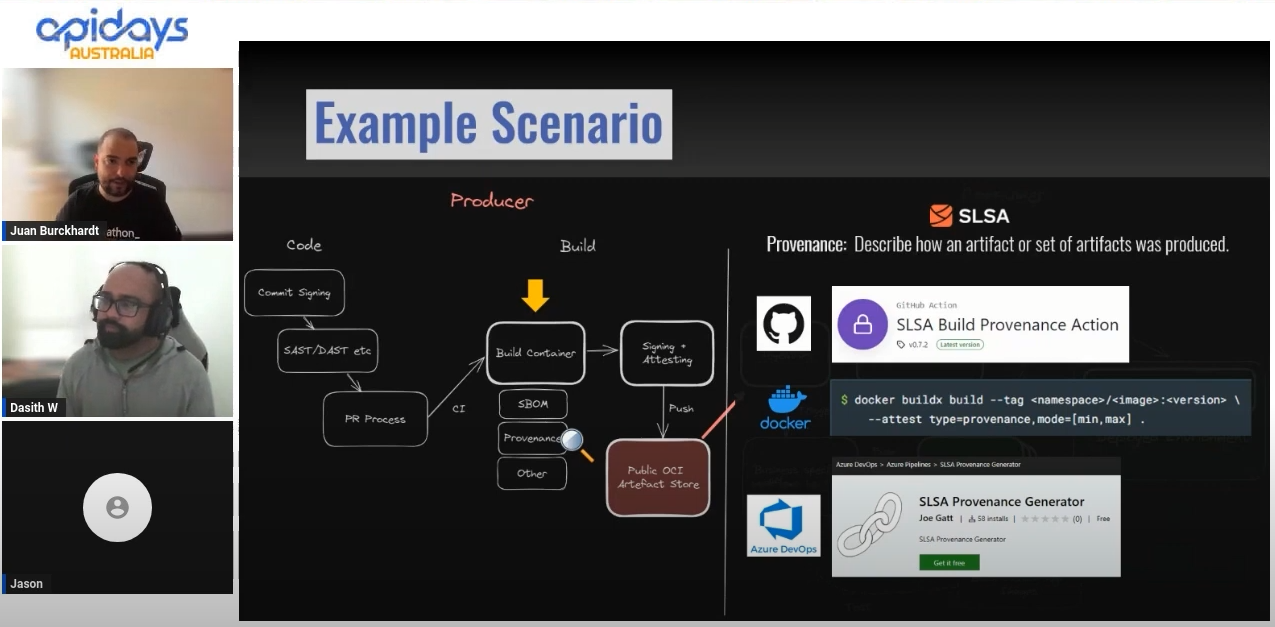
API Days & K8S Meetup 2023
Looking at the modern software supply chain security landscape. #notation #cosign #sbom #slsa #oci1.1
OCI Artifact Guidance
A contribution to the OCI image-spec refining guidance for the new top-level artifactType field introduced in OCI v1.1.

API Days Australia 2022
My team’s presentation on our learnings about EdgeDevOps can be found here.
Modern ROS2 Workspace
An opinionated, modern ROS2 (Humble) development environment in a devcontainer — integrated VS Code debugging, linting, testing, SROS2 security and CI.
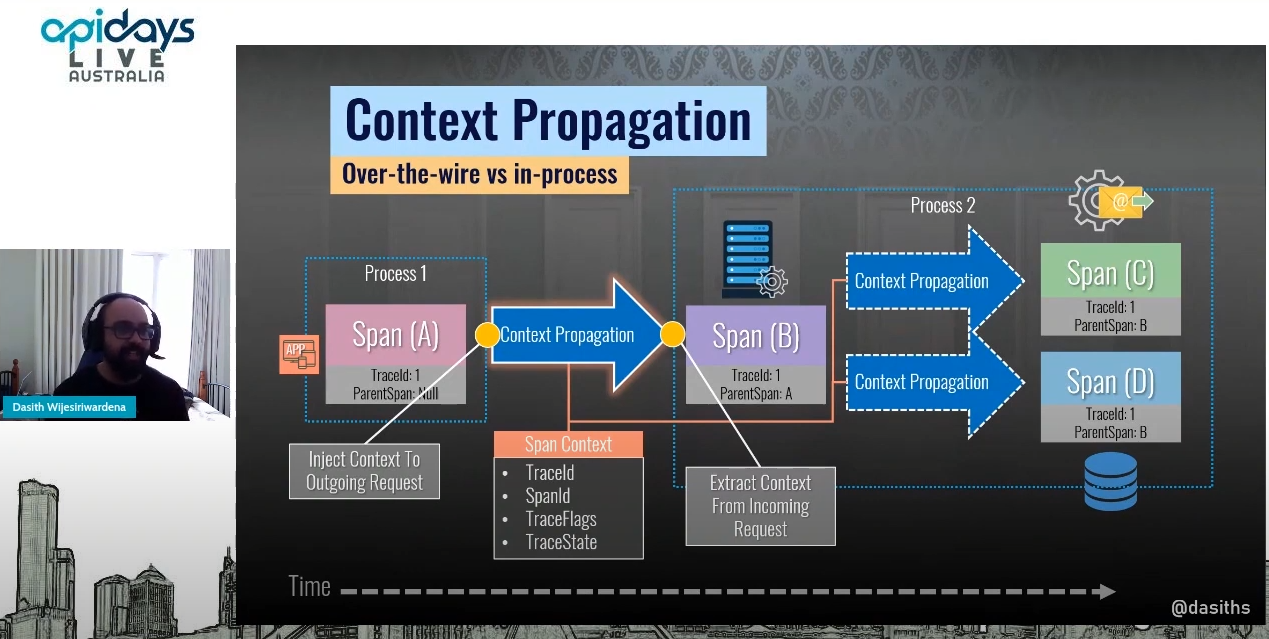
API Days Australia 2021
A live recording and slides from my session about distributed tracing and OpenTelemetry can be found here.
Hyperledger Fabric on AKS
An automated approach to deploying Hyperledger Fabric 2.x on Azure Kubernetes Service via reusable Azure DevOps pipelines and ARM templates.

API Days Jakarta 2021
A live recording and slides for my talk “The Shell Game Called Eventual Consistency” are here.

NDC Sydney 2020
A replay of “Not All Microservices Frameworks Are Made The Same” and slides are here.

OpenTelemetry Distributed Tracing
.NET and Python samples for distributed tracing with W3C trace-context and RabbitMQ/MQTT context propagation; companion to a conference talk.

API Days Live 2020
You can find a live recording of the talk I did about “building distributed systems on the shoulders of giants” here.
SimpleEndpoints
A simple, convention-based, endpoint per action pattern implementation for AspNetCore 3.0+

API Days Melbourne 2019
You can find the the slides and an extended overview of the topics I covered during my talk on Microservices here.

DDD Melbourne 2019
You can find the video recording, abstract and slides here for my talk on Modern Authentication. I covered most OAuth flows and OpenID Connect in this session.

SimpleMediator
A .NET/C# implementation of the mediator pattern with first-class support for queries, commands, events, middleware pipelines and mediation contexts.
NimbleConfig
NimbleConfig is an open source configuration injection library for .NET with full support for ASP.NET CORE. It allows you to inject configuration settings in a very simple and testable way.

#LevelsConf2018
I recently spoke about Event Sourcing at the inaugural LevelsConf 2018. You can find the abstract and slides here.
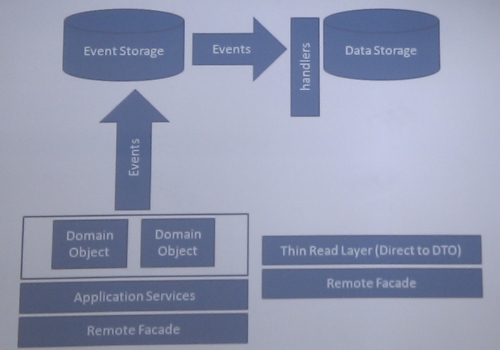
Event Sourcing Examined
A three-part deep dive into event sourcing and CQRS, from core concepts to a working NEventLite implementation.
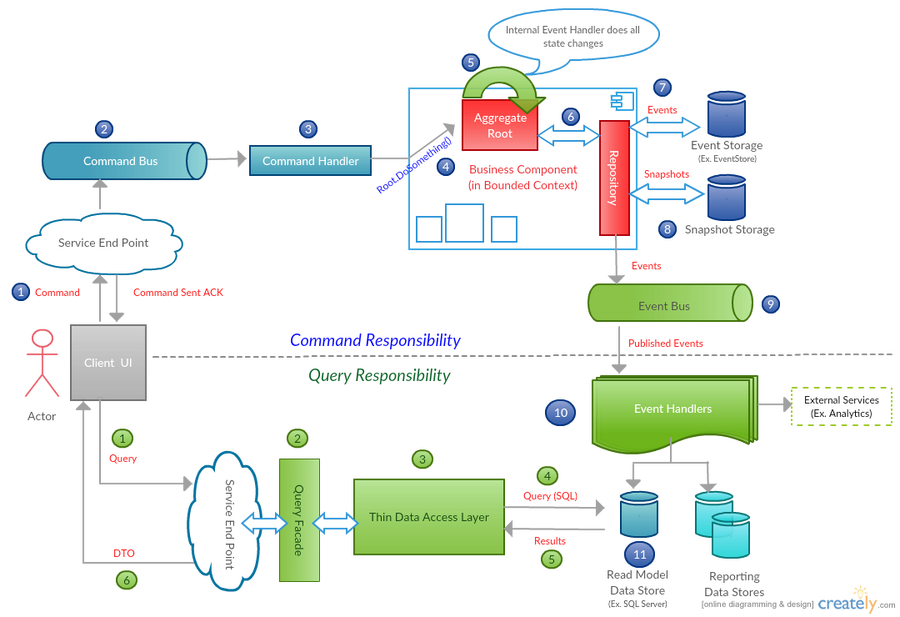
NEventLite
NEventLite is an open source Event Sourcing library for .NET that can get your ES+CQRS project up and running quickly and hassle free. It helps you manage the aggregate lifecycle and supports many event storage providers.
Continue to read my recent posts here.